
StarGAN v2 리뷰
0. Abstract
좋은 image-to-image translation 모델은 다음과 같은 특성을 가져야 합니다.
1) 생성하는 이미지의 다양성
2) 여러 domains에 대한 scalability
아직 두 가지를 모두 만족하는 모델이 없지만 StaarGAN v2는 가능하다고 합니다. 실험 결과도 base line models보다 훨씬 뛰어나다고 합니다.

1. Introduction
Image-to-image translation(IIT)은 서로 다른 visual domains간의 mapping 학습을 목표로 합니다. 여기에서 ‘domain’은 시각적으로 구분되는 카테고리를 의미합니다. 또한, 각각의 이미지는 unique appearance를 가지고 있는데 이것은 ‘style’입니다. 예를들어 성별이 ‘domain’이라면 화장, 수염, 머리스타일 등은 ‘style’에 해당합니다. 뛰어난 IIT model은 domain과 style을 자유롭게 넘나들며 이미지를 생성할 수 있어야 하는데 쉽지 않은 문제입니다.
StarGAN v1은 multi-domain translation이 가능한 초창기 모델입니다. 하지만 각각의 domain에 대해 동일한 변형만 가능했습니다. 각각의 domain이 미리 정해진 인수만을 받았기 때문입니다.
이를 개선하기 위해 StarGAN V2는 domain label을 domain-specific style code로 변경했습니다. 그래서 v2에서는 각각의 domain에서 서로 다른 style을 생성해낼 수 있게 됩니다.
이를 위해서는 두 가지 모듈이 필요한데, ‘a mapping network’와 ‘a style encoder’입니다. mapping network는 random Gaussian noise를 style code로 변환하고, style encoder는 given reference image에서 style code를 추출해냅니다. style code의 활용은 매우 성공적이었으며, 이를 통해 다양한 domains의 다양한 이미지들을 합성할 수 있었다고 합니다.
2. StarGAN v2
2.1 Proposed framework
본 논문의 목표는 x에 상응하는 y domain의 다양한 이미지들을 단 하나의 생성기 G로 만들어내는 것입니다. 이를 위해 domain-specific style vectors를 학습된 domain별 style 공간에서 생성하고, 해당 style을 G가 학습하게 합니다.
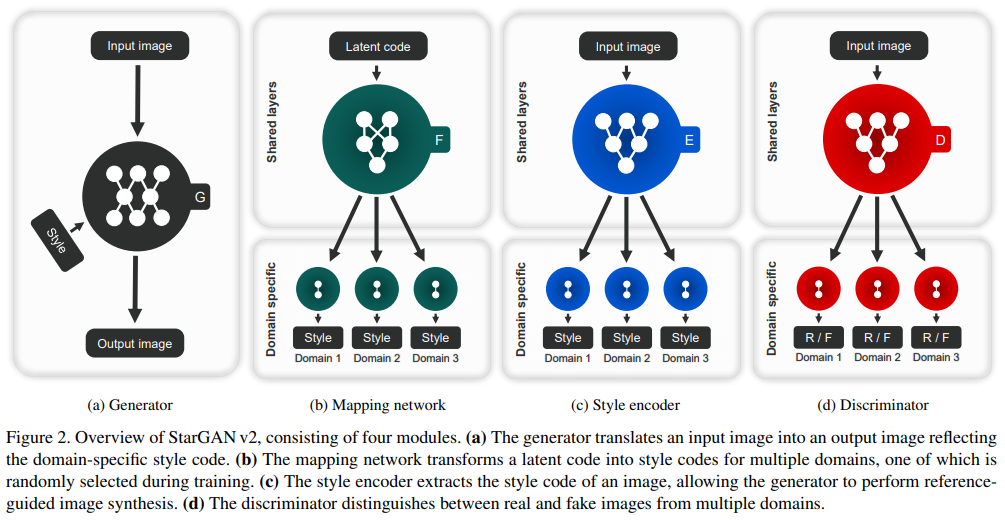
Generator (Figure 2a)
생성기 G는 input image x와 style code s를 받아 output image G(x,s)를 생성합니다. s는 mapping network F 또는 style encoder E에 의해 제공됩니다. s를 G에 주입하기 위해 adaptive instance normalization(AdaIN) 방법을 활용했습니다. s를 제공함으로써 y의 스타일을 따라하므로, G에 직접적으로 y를 제공할 필요는 없어졌습니다.
Mapping network (figure 2b)
latent code $z$와 domain $y$에서 mapping network F는 style code $s=F_y(z)$를 생성합니다.F는 모든 가능한 domains에 대해 style codes를 생성할 수 있도록 MLP로 구성됐습니다.F는 latent vector $z \in Z$와 domain $y \in Y$의 random sample에서 다양한 style codes를 생성합니다.
Style encoder (figure 2c)
$x$와 $y$에서 encoder E는 style code $s = E_y(x)$를 추출합니다. F와 마찬가지로 E는 multi-task 학습용 설정입니다.E는 서로 다른 참조 이미지에서 다양한 style codes를 생성합니다.덕분에 G는 style $s$를 참조 이미지 $x$에 반영해서 결과 이미지를 합성할 수 있습니다.
Discriminator (Figure 2d)
구별자 D도 multi-task용이므로 multiple output을 생성합니다. 각 domain $y$에 대해 input 이미지가 진짜인지 가짜인지 binary classification을 수행합니다.
2.2 Training objectives
$x \in \mathcal{X}$는 주어진 이미지이고, 이미지의 본래 domain이 $y \in \mathcal{Y}$일 때 다음과 같이 학습을 했습니다.
Adversarial objective
학습중에 먼저 latent code $z \in \mathcal{z}$와 목표 domain $\tilde{y} \in \mathcal{y}$를 임의로 추출합니다.그리고 목표 style code $\tilde{s} = F_{\tilde{y}}(z)$를 생성합니다. 생성기 G는 $x, \tilde{s}$를 input으로 받고 adversarial loss로 학습합니다.
Style reconstruction
생성자 G가 style code 𝑠̃ 를 더 잘 활용하도록 style reconstruction loss로 학습합니다.
본 논문에서의 주목할 점은 하나의 encoder E로 여러 domains에 대한 다양한 outputs를 생성한다는 점입니다.
Style diversification
생성자 G가 다양한 이미지들을 만들어낼 수 있도록 diversity sensitive loss를 적용해 정규화합니다.
$\tilde{s}_1$ 과 $\tilde{s}_2$ 는 두 개의 임의 latent codes $z_1, z_2$를 mapping network F에 넣어 생성합니다. 정규화 수식 (3)은 G가 이미지 공간을 더 탐색하게 하고, 의미있는 style features를 찾아내도록 합니다.

Preserving source characteristics
(1) ~ (3)은 생성된 이미지 $G(x,\tilde{s})$가 적절하게 input 이미지의 domain-invariant 특징을 유지할 수 있도록 도와주지 못합니다. 그래서 다음과 같은 cycle consistency loss를 도입했습니다.
$\hat{s} = E_y(x)$는 input 이미지 $x$의 style code입니다. (4)를 통해 G는 원본 이미지의 특징을 잘 유지할 수 있습니다.
Full objective
3.Experiments
3.1 Analysis of individual components
실험의 basic setup은 StarGAN으로, WGAN-GP, ACGAN discriminator, depth-wise concatenation이 적용됐습니다. V2로의 변경을 위해 먼저 discriminator를 multi-task D로 교체했습니다. 또한, 최신 GAN 방법론들의 장점을 이식하기 위해 R1 regularization을 적용하고, depth-wise concatenation을 adaptive instance normalization(AdaIN)으로 변경했습니다.
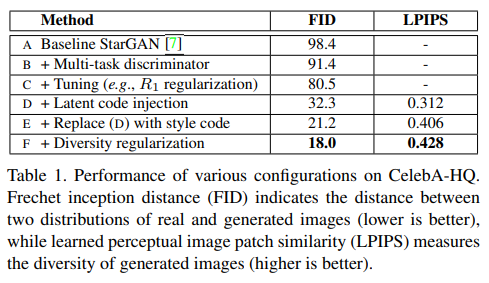
시각적 결과 품질 확인

