
Knowledge distillation: A good teacher is patient and consistent
0. Abstract
매우 큰 SOTA 모델들과 실제 활용 가능한 수준의 모형 간 성능 불일치가 증가하고 있다. 본 논문에서는 그 격차를 좁힐 수 있는 방법에 대해 연구를 진행했다.
- KD를 활용하여 성능의 손실 거의 없이 실용적 크기의 model로 압축하는 방법을 소개한다.
- 추가로, 몇가지 디자인 방법들이 distillation 성능에 크게 영향을 주는 것을 밝혀냈다.
1. Introduction
최근 SOTA 모델들은 hardware의 한계치까지 사이즈가 커지고 있으나, 너무 사이즈가 커서 실제로는 쓸 수가 없다. 그래서 좋은 성능의 모형을 더 작게 압축하는 방법으로는 다음과 같은 두 가지 방법이 있다.
- model pruning: 적용하기에 문제가 많음
- knowledge distillation: 적절
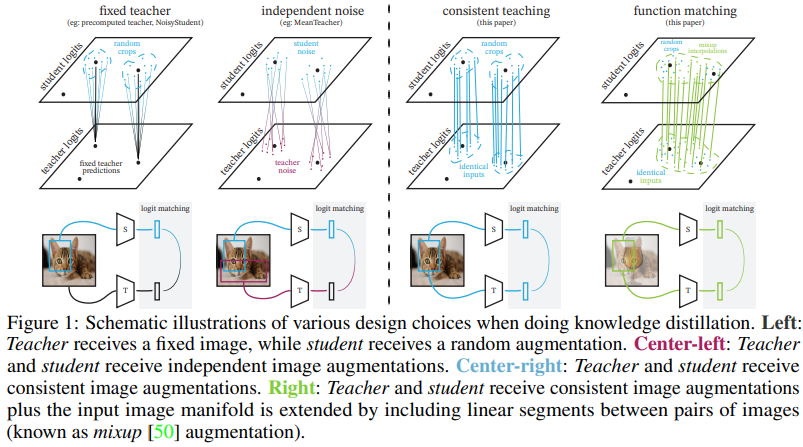
본 논문에서는 KD를 teacher와 student가 만들어내는 functions의 일치과정으로 해석했다. 이러한 관점에서, 두 가지 중요한 원리를 발견했다.
- 첫 번째로는 teacher와 student에 동일한 image input을 제공해야 한다는 것 (crop, augmentations 등)
- 두 번째는 “consistent image views”, “aggressive augmentations” and “very long training schedules”가 매우 중요하다는 것
두 가지 발견이 간단해보이지만, 이전 연구들에서 제외된 이유들이 있다.
- 먼저, teacher가 매우 큰 경우 연산 부담을 줄이기 위해 teacher를 먼저 학습하고자 한다.
- 그리고, KD는 model compression 외 다른 목적으로도 많이 사용된다.
- 마지막으로, KD는 지도학습보다 훨씬 많은 epoch 학습이 필요해서 일반적인 길이로 학습하는 경우 원하는 효과를 얻을 수 없다는 것이다.
2. Experimental setup
Datasets, metrics and evaluation protocal
datasets은 다음과 같은 다섯가지를 사용했다. 여러 데이터들을 사용하여 클래스 수도 37 ~ 1000개로 다양하고, 학습데이터 수도 1020 ~ 1281167개로 차이가 큰 조건을 만들었다. 성능 측정은 test set의 Accuracy를 기준으로 한다.
- flowers102, pets, food101, sun397, ImagenNet(ILSVRC-2012)
Teacher and student models
- Teacher: BiT (BiT-M-R152x2) pretrained on ImageNet-21k
- pre-trained on ImageNet-21k
- Student: BiT-ResNet-50
Distillation loss
- KL-divergence between T and S
- hard labels는 사용하지 않음
- Temperature(adjust the entropy of the predicted softmax-probability distributions) 사용
Training setup
- Adam with default params
- cosine LR schedule without warm restarts
- gradient clipping with a threshold of 1.0 on the global L2-norm of a gradient
- 기본적으로 batch size 512. ImageNet 실험만 large batch size 4096
3. Distillation for model compression
3.1 Investigating the “consistent and patient teacher” hypothesis
본 섹션에서 Distillation을 function matching으로 해석할 때 가장 좋은 성능을 얻을 수 있음을 실험적으로 증명한다. 또한 네 개의 소형~중형 크기의 여러 데이터들을 사용해서 robustness도 함께 검증했다. 그리고 다른 요인의 개입을 막기 위해 hyper params를 다음으로 고정했다.
- learning rates: {0.0003, 0.001, 0.003, 0.01}
- weight decays: {1 · 10−5 , 3 · 10−5 , 1 · 10−4 , 3 · 10−4 , 1 · 10−3}
- distillation temperatures: {1, 2, 5, 10}
3.1.1 Importance of “consistent” teaching
가장 먼저 언급할 점은, student와 teacher 모두 같은 이미지(views)로 학습을 할 때 모든 데이터 셋에서 최고의 성능을 보여준다는 것이다.
- Fixed teacher: 미리 학습한 teacher을 활용해서 고정된 예측값으로 student를 학습했다. 가장 간단하면서도 가장 성능이 좋지 않은 방법은 “fix/rs”였다. rs는 teacher, student 모두의 이미지를 224*224px로 강제 변환하는 것이다. “fix/cc”는 teacher는 central crop을 사용하고, student에서는 mild random crop을 사용하는 방법이다. “fix/ic_ens”은 data augmentation을 강하게 하는 것으로 teacher의 성능 향상에 좋고, student도 random inception crops를 사용한다.
- Independent noise: “ind/rc”는 teacher, student 모두에게 2 independent mild random crops. “ind/ic”는 heavier inception crop을 대신 사용한다.
- Consistent teaching: mild random cropping (same/rc) 또는 heavy inception crop (same/ic)을 적용하고 teacher와 student 모두에 동일하게 사용한다.
- Function matching: Consistent 학습에서 mixup을 추가로 적용합니다. FunMatch로 명명하기도 한다.
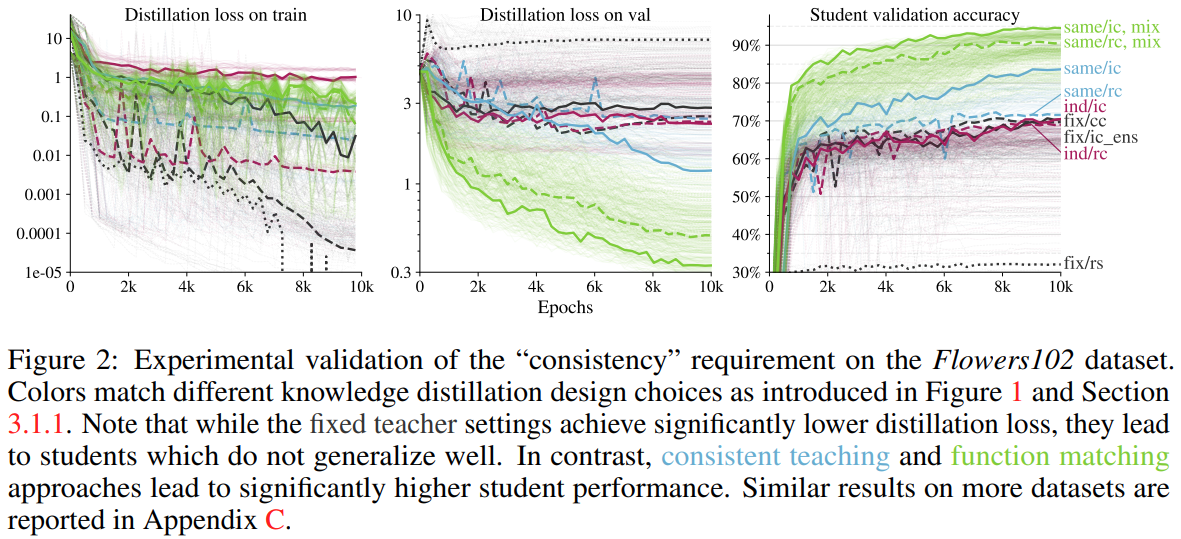
위의 Figure2는 Flowers102 데이터셋에 대한 10000 epoch 학습 그래프이다. 여기에서 “Consistency”의 중요성을 확인할 수 있다.
3.1.2 Importance of “patient” teaching
distillation을 a variant of supervised learning으로 해석할 수도 있다. 그러나 이러한 관점은 모든 standard supervised learning의 문제들을 계승한다. 예를들어 aggressive data augmentations는 라벨을 잘못 알려줄 수 있고, less aggressive augmentations은 overfitting 우려를 야기한다.
그러나 distillation을 function matching이라고 생각하기 시작하면 결과물이 크게 바뀐다. 같은 input을 사용하므로 강한 augmentation을 할 수 있다.
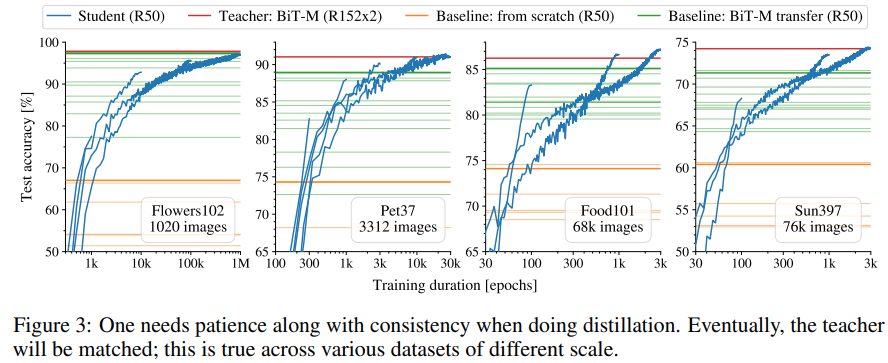
새로운 방법으로 학습하는 경우 항상 teacher 만큼의 성능을 student가 달성하는 경향을 확인할 수 있었다. 특히나 100만 epoch을 학습함에도 overfitting sign을 발견할 수 없었다는 점이 인상적이다.
3.2 Scaling up to ImageNet
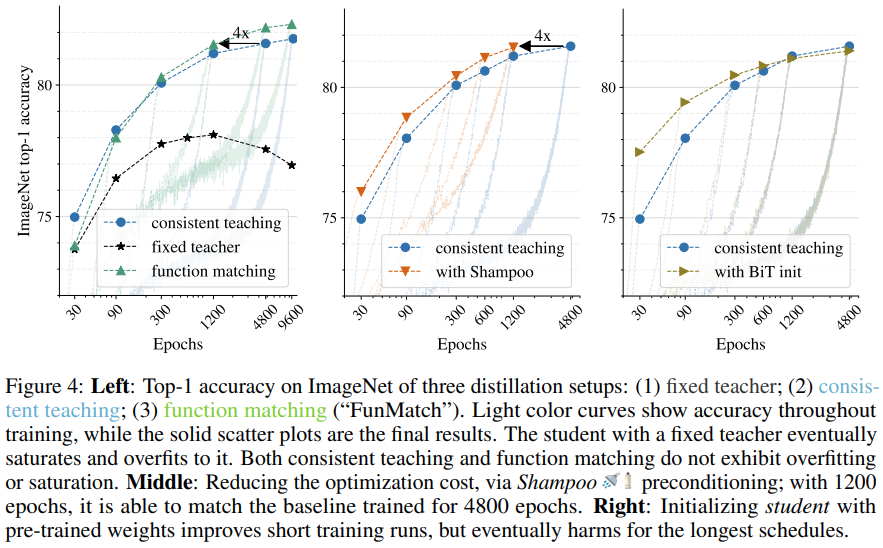
이전 실험에서 발견한 사항을 ImageNet 등의 더 어려운 환경에서도 사용 할 수 있을지 연구했다. 아래의 Figure 4가 ImageNet에 대한 실험 결과이다. 즉, ImageNet에서도 이전의 발견이 적용됨을 확인할 수 있었다.
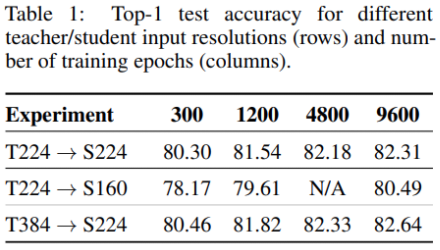
3.3 Distilling across different input resolutions
지금까지 teacher와 student가 동일한 해상도의 input을 사용하는 세팅이었다. 그러나 일반적으로는 다른 해상도의 input을 사용할 수도 있다. 그래서 the original high-resolution image를 crop하고, the student and the teacher에 대해 다르게 resize하는 방법이 있다.
또한, 384에서 fine-tuned한 teacher을 사용하고, student는 그대로 두는 것이다.
3.4 Optimization: A second order preconditioner improves training efficiency
Figure4 실험에서 optimizer로 Shampoo를 사용하였을 때, 더 빨리 목표 정확도를 달성하는 것을 확인할 수 있었다. 그러나 일반적으로는 Adam에서의 성능이 더 우수한 것으로 나타났다.
3.5 Optimization: A good initialization improves short runs but eventually falls behind
좋은 initialized model이 빠르게 좋은 성능을 찾지만, 결과적으로 오래 학습하는 경우 from scratch로 학습하는 student의 결과가 Figure4 오른쪽 그래프와 같이 더 좋아진다.
3.6 Distilling across different model families
서로 다른 구조의 teacher - student 관계에서도 좋은 결과를 보여주는지 실험을 진행했다. 두 가지를 중점적으로 확인했는데, 앙상블 teacher를 사용하는 경우 성능이 더 좋아지는지, 그리고 더 작고 효율적인 student 모형을 사용했을 때 성능이 유지되는지를 살펴보았다.
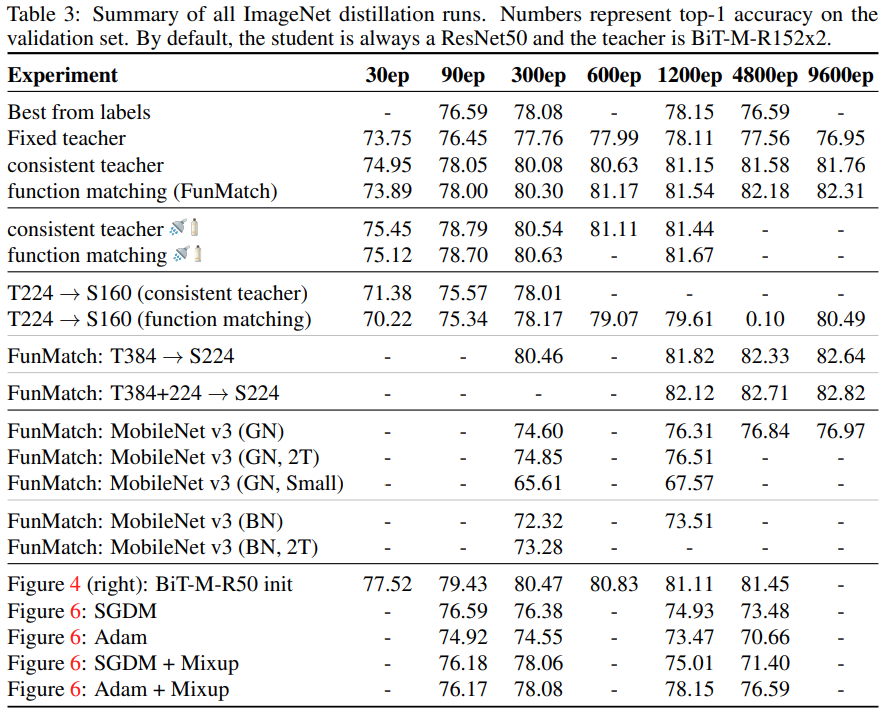
3.7 Comparison to the results from literature.
ResNet-50 모형에 대해 지금까지 발표된 최고의 논문들보다 좋은 성능을 이끌어 냈다.
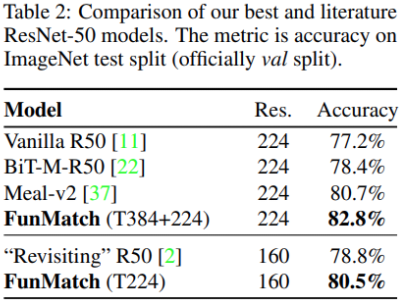
3.8 Distilling on the “out-of-domain” data
지금까지는 동일 domain에서의 실험만 진행했는데, 다른 domain에 대한 실험도 진행해보았다.
- 일단 동일 domain에서의 성능이 제일 뛰어나다.
- domain이 크게 다르더라도 어느정도는 distillation의 효과를 보여주었다.
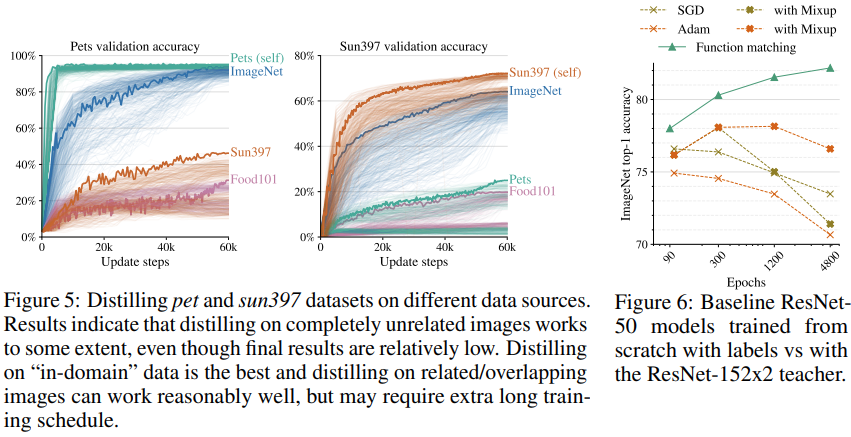
3.9 Finetuning ResNet-50 with mixup and augmentations
단순히 mixup을 쓰고, 오래 학습하기만 하면 되는 것 아닌지 생각할 수도 있다. 그래서 동일한 baseline에서 ImageNet을 사용해서 지도학습으로 mixup을 쓰고 많은 epoch으로 학습을 해보았다. Figure 6와 같이 distillation이 없이는 제대로 학습되지 않았다.