
Emerging Properties in Self-Supervised Vision Transformers (DINO)
0. Abstract
본 논문은 “Vision Transformer(ViT)에 self-supervised learning를 적용하여 CNN에 버금가는 새로운 properties를 추출할 수 있을까?”라는 가설을 검증합니다.

self-supervised 방법론을 ViT에 적용하며, 다음과 같은 발견이 있었습니다.
- self-supervised ViT(ssViT) features는 이미지의 semantic segmentation에 대한 명확한 정보가 있지만 지금까지 드러나지 않음
- 또한, ssViT features는 훌륭한 k-NN 분류기가 될 수 있으며, ImageNet에서 78.3%의 top-1 accuracy를 보임
- 그리고 이번 연구에서 momentum encoder, multi-crop training, 그리고 작은 patch size의 중요성을 다시 한 번 더 확인하게 됨
1. Introduction
Transformers는 최근 visual recognition 분야에서 CNN의 대안으로 급격히 부상했습니다. 이것은 NLP의 학습 전략을 가져온 것으로, 대용량 데이터에서의 사전학습 후 목표 dataset에서의 재학습을 진행합니다. 그러나 ViT는 계산량도 많고, 데이터도 더 많이 필요한데 CNN 대비 명확한 이점을 찾기 어려웠습니다.
본 논문에서는 사전학습 단계에서 지도학습을 적용해서 ViT의 성공을 설명해보려 합니다. 왜냐하면 NLP에서 Transformers의 성공은 self-supervised 사전학습이라 생각했기 때문입니다.
- self-supervised 사전학습의 목적은 문장 내 단어들로 “pretext tasks”를 만들어 문장 별 라벨이 하나인 지도학습보다 학습이 더 잘 되도록 하는 것
- 이미지 영역에서도 지도학습은 이미지 내의 풍부한 시각적 정보들을 놓치고, 오직 주어진 한 개의 라벨과의 관련성만을 고려하게됨

NLP에서 사용된 self-supervised pretext tasks는 텍스트 기반이지만, 다양한 이전 연구들이 이미지 영역에서의 활용을 시도해왔습니다. 지난 연구들이 모두 비슷한 구조를 공유하지만, 저마다 조금씩 다른 요소를 사용해서 기존의 문제를 해결하거나 성능을 향상시켜왔습니다.
- ssViT features는 “scene layout”을 갖고 있으며, 특히 Figure1에서 처럼 객체 경계를 잘 파악할 수 있음. 이러한 정보는 마지막 블록의 self-attention modules에서 바로 가져올 수 있음
- ssViT features는 finetuning, linear classifier, 데이터증분(DA) 없이도 좋은 성능의 k-NN 분류기가 됨
- ImageNet에서 78.3%의 top-1 accuracy 달성
Segmentation masks의 탈피는 self-supervised 방법론들의 공통된 특징으로 여겨지고 있습니다. 그러나 성능 좋은 k-NN 분류기는 momentum encoder, multi-crop augmentation 등의 몇 가지 요소들을 사용할 때만 얻을 수 있었습니다. 또 다른 본 연구에서의 발견은 더 작은 patches를 사용할 때 더 좋은 결과를 얻는다는 것입니다.
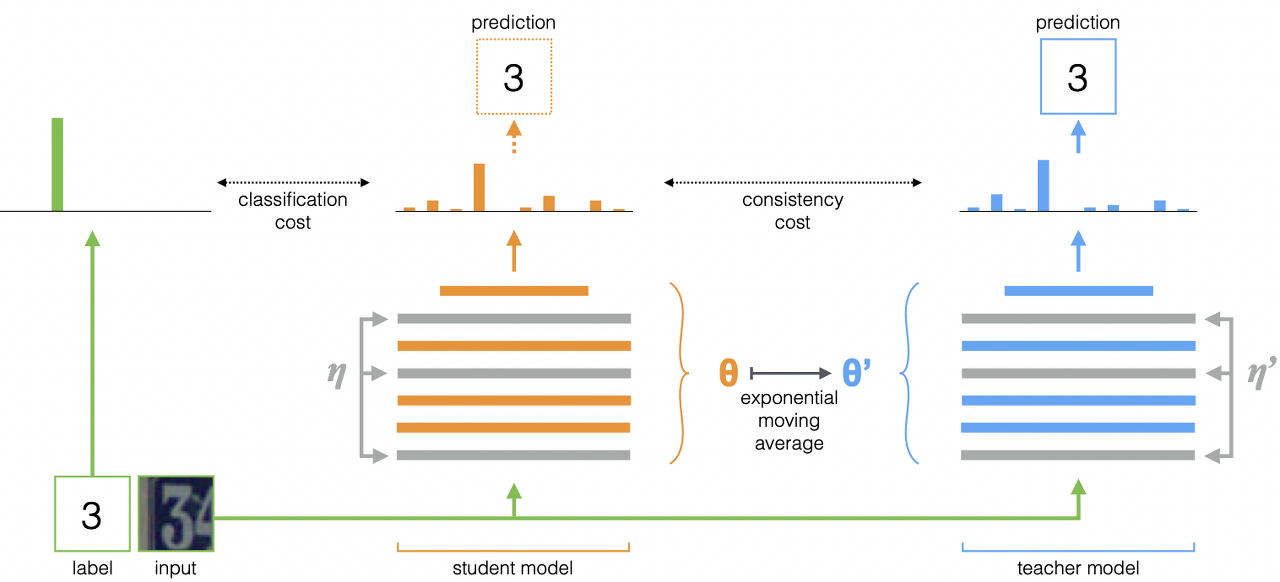
이러한 요소들의 중요성을 발견한 것은 일종의 라벨 없는 “knowledge distillation”으로 해석될 수 있는 쉬운 self-supervised 방법론을 제시한다는 가치가 있습니다. 여기에서 제안하는 framework인 DINO는 momentum encoder로 만들어진, teacher network로부터 바로 예측 결과를 얻어 쉽게 self-supervised 학습을 할 수 있습니다. 흥미롭게도, DINO에서는 teacher network의 결과를 centering and sharpening하는 것만으로도 collapse를 피할 수 있었습니다. 반면에 다른 유명한 장치들인 predictor, advanced normalization, contrastive loss 등은 안정성/성능 측면에서 효용이 매우 적었습니다. 요약해서 다시 강조하자면, DINO는 구조의 변경과 internal normalizations 없이도 유연하고 convnets와 ViTs에서 모두 잘 동작합니다.
ImageNet classificatioin benchmark에서 80.1%의 top-1 accuracy를 보임으로써 DINO와 ViT의 시너지를 검증해냈습니다. 또한, DINO가 convnets에서도 잘 작동함을 ResNet-50 구조에 적용하여 보였습니다. 마지막으로, 제한된 computation, memory에서의 DINO+ViTs 상황들에 대한 연구도 진행하여 이전의 (유사한 모델 사이즈의) self-supervised convnets 결과들 대비 압도적인 결과를 얻어냈습니다.
- just two 8-GPU severs
- over 3days
- 76.1% on Imagenet
2. Related Work
Self-supervised learning
본 연구는 BYOL의 방법론을 차용하나, 다른 loss를 사용하는 것과 완벽하게 동일한 구조의 student, teatcher 네트워크를 생성한다는 점에서 차이가 있습니다.
Self-training and knowledge distillation
이전 연구들이 self-supervised learning과 knowledge distillation을 결합하여 model compression 및 성능 향상을 이루었습니다. 그러나 이전 방법들은 고정된 사전학습 teacher network를 사용하지만, 본 연구에서는 dynamically built teacher network를 사용합니다. 본 방법은 “codistillation”으로 정의될 수도 있으며, student와 teacher가 동일한 구조로 함께 학습된다는 특징이 있습니다.
3. Approach
3.1 SSL with Knowledge Distillation
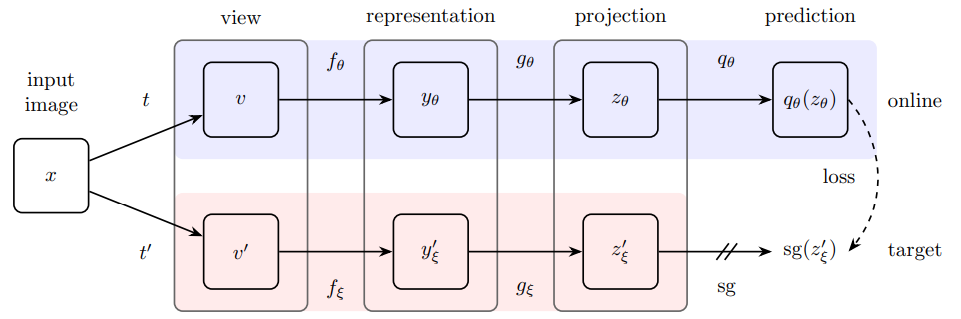
본 논문에서 제안하는 framework인 DINO의 구조는 Figure 2 참조.

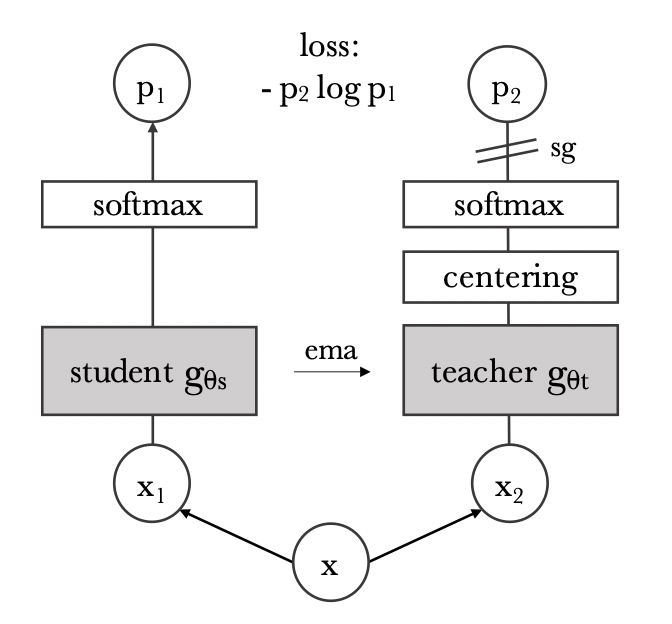
Knowledge distillation 방법론은 student network $ g_{\theta_s} $를 teacher network $ g_{\theta_t} $의 결과를 가지고 학습을 하는 것입니다. 한 개의 이미지 $ x $에 다음의 softmax function을 이용해 $ K $ 차원의 확률분포를 생성할 수 있습니다. teacher - student loss는 cross-entropy loss(formula 1)를 사용합니다.
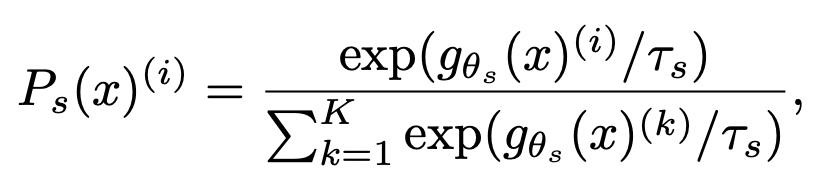
cross-entropy loss를 적용하기 위해 먼저 이미지의 crop 또는 distorted view를 생성합니다. 이것을 더욱 구체적으로 설명하면, 1개의 이미지에서 V views를 생성하는 것입니다. 이 set은 두 개의 global veiws $x^g_1, x^g_2$와 더 작은 화질의 여러개의 local views로 구성됩니다. student network에는 모든 crops가 통과하지만, teacher network에는 global views만 통과합니다.
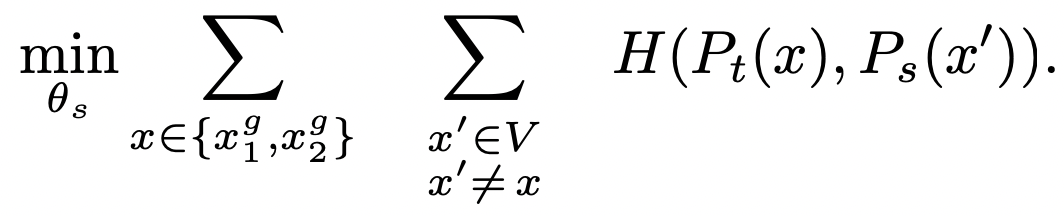
이렇게 정의한 loss는 2이상의 어떤 수의 views에서 사용 가능합니다. 그러나 multi-crop의 표준 세팅에 따라 2242 resolution의 2 global views 및 962 resolution의 local views를 사용합니다. 본 세팅은 별도의 언급이 없다면 DINO의 기본 세팅으로 사용됩니다.
- student와 teacher 모두 동일한 architecture g를 사용
- 물론 parameters는 서로 다름 $\theta_s, \theta_t$
teacher network
일반적인 knowledge distillation 방법들과 달리, DINO는 이미 학습된 teacher network를 사용하지 않습니다. 그 대신, student network의 past iterations에서 가져옵니다. 그런데 teacher network를 1 에폭씩 고정하는 것이 놀랄정도로 잘 작동했으며, student를 그대로 복사하는 것은 converge하지 않았습니다.
그리고 momentum encoder 등에서 student weights에 EMA를 적용하는 것이 DINO framework에 잘 어울렸습니다. update rule은 다음과 같으며 λ는 학습 과정에서 코사인 스케쥴을 따라 0.996에서 1로 점차 증가합니다. \(θ_t ← λθ_t + (1 − λ)θ_s\)
원래 momentum encoder는 contrastive learning에서 queue 대신 도입됐습니다. 그러나 DINO에서는 queue, contrastive loss 둘 다 없으므로 mean teacher의 역할에 더 가깝다 볼 수 있습니다.
실제로 DINO의 teacher는 “Polyak-Ruppert averaging with an exponential decay” 같은 ensembling 방법처럼 동작합니다. “Polyak-Ruppert averaging ensembling”은 모델 성능 향상을 위해 실전에서 일반적으로 많이 사용하는 방법입니다. 이번 연구에서 teacher가 학습 내내 더 좋은 성능을 내는 것을 확인했고, 그 덕분에 student network가 잘 학습될 수 있었습니다.
Network Architecture
네트워크 구조는 다음과 같습니다.
- 네트워크 backbone f: ViT, ResNet
- projection head h: $h: g = g \circ h$
- downstream tasks를 위한 features: f의 output
- h: 3-layer MLP
- 은닉층: L2 norm, weight norm가 적용된 2048 차원의 fully connected layer
- SwAV와 비슷
BYOL과 siamese representation learning(2020)에서 사용한 predictor는 student/teacher 모두에서 사용하지 않았습니다. 그리고 ViT는 convnets과 달리 BN을 안 쓰는 것이 default. 그러므로 DINO-ViT는 projection heads 포함 그 어디에서도 BN을 사용하지 않습니다.
Avoiding collapse
self-supervised 방법들마다 collapse를 방지하기 위해 서로 다른 방법들을 차용합니다. 예를 들면,
- contrastive loss
- clustering constraints
- predictor
- Batch Normalizations
DINO에서도 multiple normalizations를 써서 안정화 할 수도 있지만, “centering and sharpening of the momentum teacher outputs”만으로도 안정화가 가능했습니다.
“centering”은 한 개의 차원이 dominate하는 것을 막지만, uniform distribution으로 수렴하게 만듭니다. “sharpening”은 그 반대로 작용하지요. 그러므로 두 개의 작업이 균형을 이루도록 둘 다 반영하여 collapse를 방지할 수 있습니다.
# dino/main_dino.py
def forward(self, student_output, teacher_output, epoch):
"""
Cross-entropy between softmax outputs of the teacher and student networks.
"""
student_out = student_output / self.student_temp
student_out = student_out.chunk(self.ncrops)
# teacher centering and sharpening
temp = self.teacher_temp_schedule[epoch]
teacher_out = F.softmax((teacher_output - self.center) / temp, dim=-1)
teacher_out = teacher_out.detach().chunk(2)
total_loss = 0
n_loss_terms = 0
for iq, q in enumerate(teacher_out):
for v in range(len(student_out)):
if v == iq:
# we skip cases where student and teacher operate on the same view
continue
loss = torch.sum(-q * F.log_softmax(student_out[v], dim=-1), dim=-1)
total_loss += loss.mean()
n_loss_terms += 1
total_loss /= n_loss_terms
self.update_center(teacher_output)
return total_loss
@torch.no_grad()
def update_center(self, teacher_output):
"""
Update center used for teacher output.
"""
batch_center = torch.sum(teacher_output, dim=0, keepdim=True)
dist.all_reduce(batch_center)
batch_center = batch_center / (len(teacher_output) * dist.get_world_size())
# ema update
self.center = self.center * self.center_momentum + batch_center * (1 - self.center_momentum)
center c는 EMA로 업데이트되며, 이러한 방법은 여러 배치 사이즈에서도 잘 작동하게 하고 있습니다.
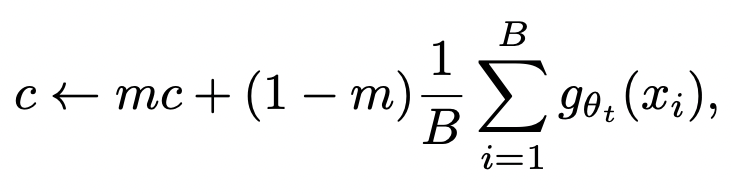
위 식에서 m > 0 은 EMA rate parameter이며, B는 배치사이즈입니다. Output sharpening은 teacher softmax normalization의 temperature 변수 $τ_t$를 작게 해서 적용할 수 있습니다.
3.2 Implementation and evaluation protocols
Vision Transformer
ViT는 Vaswani et al. 논문을 준용하고, image로의 적용은 Dosovitskiy et al. 논문을 참고했습니다. 구현은 DeiT 을 따라했습니다.
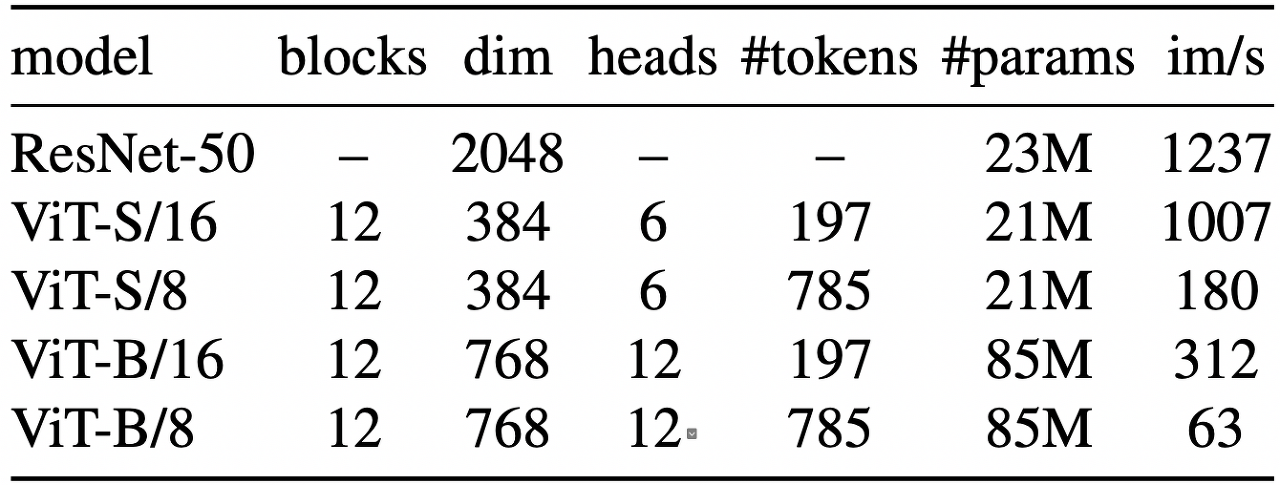
- 여러 네트워크들의 configuration을 Table 1에 요약
4. Main Results
4.1 Comparing with SSL frameworks on ImageNet
Comparing with the same architecture
Table 2에서 DINO와 다른 self-supervised 방법들을 비교합니다. ViT-small은 DeiT-S를 참조합니다. ViT-S를 선택한 이유는 다음과 같이 ResNet-50과 여러 면에서 비슷하기 때문입니다.
- parameters: 21M ↔ 23M
- throughput: 1237 ↔ 1007 (img/sec)
- supervised performace: 79.3% ↔ 79.8%
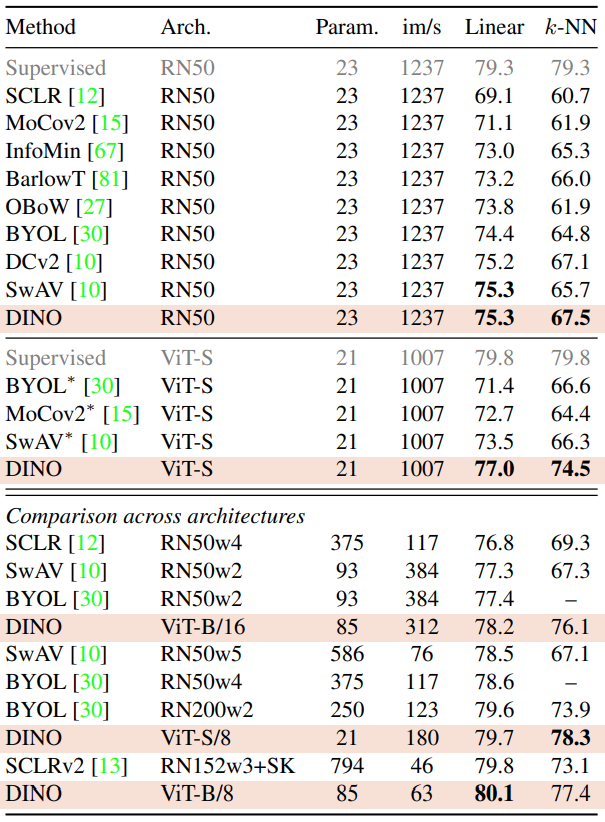
일단 ResNet-50 에서는 겨우 1등을 하기는 했습니다만, ViT-small 에서는 BYOL을 outperform 합니다. 신기한 점은 k-NN을 써도 linear classifier을 쓴것만큼 성능이 잘 나온다는 것입니다.
테이블 아래쪽에서는 각 아키텍처의 가장 좋은 세팅을 가져왔습니다.
- patch size가 8일 때가 16일 때보다 성능이 잘 나옴
- 파라미터 수는 증가하지 않지만, 메모리/러닝타임 측면에서 안좋은 것은 사실
- 하지만 최종 성능이 제일 좋음!
4.2 Properties of ViT trained with SSL
4.2.1 Nearest neighbor retrieval with DINO ViT
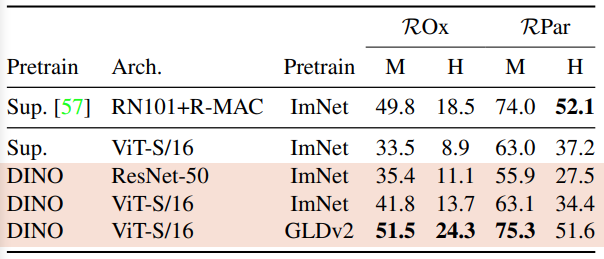
Image Retrieval
Oxford and Paris image retrieval datasets을 사용했습니다. 이 데이터는 3개의 난이도 세트가 있습니다. M는 Medium, H는 Hard를 의미합니다.
features는 그대로 둔 채, k-NN만을 써서 이미지를 검색했습니다. supervised보다 높은 성능을 내는 대단한 결과를 보여줍니다.
DINO는 Google Landmarks v2의 1.2M clean set으로 학습시켰습니다. SSL 방법론이라서 어떤 데이터든지 라벨 없이 학습이 가능하기 때문에 가능합니다.
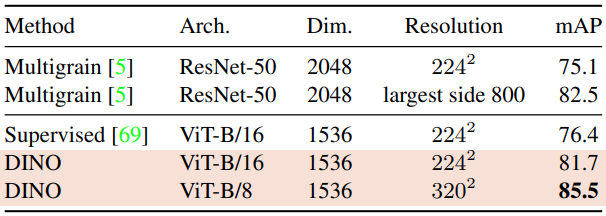
Copy detection
INRIA Copydays dataset에서 “strong” subset을 사용했습니다. 이전 연구들을 따라서 YFCC100M dataset에서 랜덤하게 10k의 distractor images를 추가했습니다. copy detection은 features의 코싸인 유사도를 바로 계산합니다. 모형의 학습은 YFCC100M에서 추가로 20K random images를 가져와서 진행했습니다.
4.2.2 Discovering the semantic layout of scenes
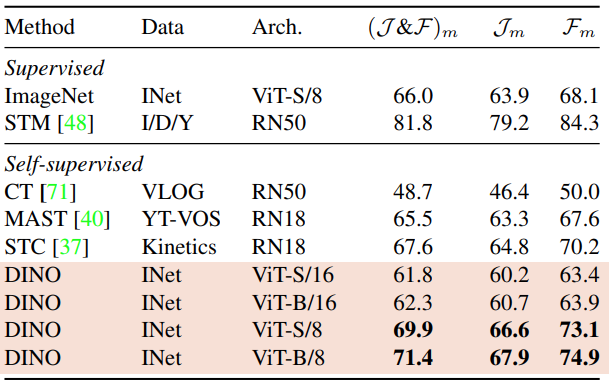
Video instance segmentation
DAVIS-2017 video instance segmentation benchmark를 사용하여, 아래 Table 5에 성능을 비교했습니다.
Probing the self-attention map
Figure 3에서 head 별 서로 다른 semantic regions에 집중하고 있는 것을 볼 수 있습니다. 말 털이나, 작은 깃발까지도 잘 잡는 모습을 보여줍니다.

Figure 4에서 supervised ViT가 오히려 semantic segmentation을 더 잘 잡지 못하는 것을 확인할 수 있습니다.

4.2.3 Transfer learning on downstream tasks
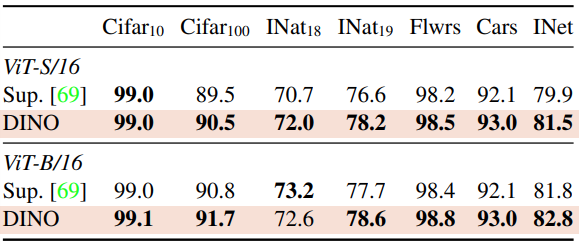
Table 6를 보면, downstream tasks 들에 대한 성능을 supervised와 비교할 수 있습니다.
5. Ablation Study of DINO
5.1. Importance of the Different Components
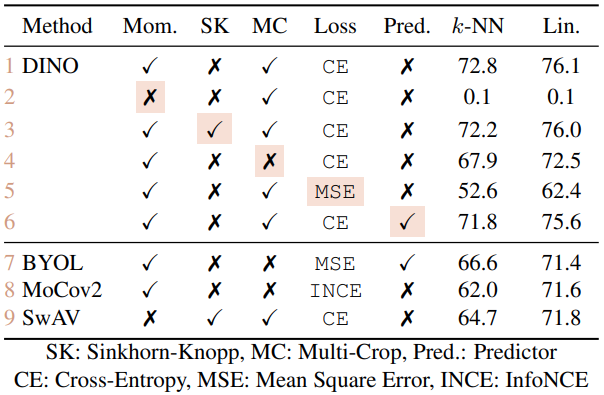
Table 7에 components가 추가될 때의 효과에 대해서 분석해서 정리했습니다.
- 일단 momentum이 없으면 framework 동작이 불가
- SK는 collapse를 피하기 위해서 필요하지만, momentum과 같이 쓰는 경우 효과가 별로 없음
- 3행과 9행을 비교해보면 momentum의 큰 효과를 확인할 수 있음
- 4행과 5행을 비교해보면 MC, CE가 성능 향상에 중요함을 확인 가능
- 6행을 보면, student network에 predictor를 추가하는 것은 효과가 별로 없음(BYOL에서는 크리티컬)
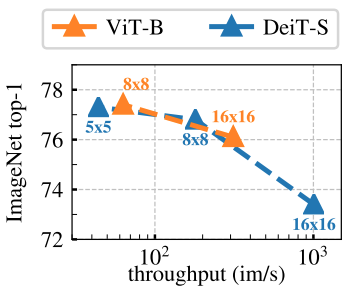
Comparing with the same architecture
Figure 5에는 patch size에 따른 k-NN classification 성능을 표로 나타냈습니다. 모든 모델은 300 epochs 학습했습니다.
- 결과를 보면 patch size가 작아질수록 성능 향상이 크게 일어나는 것을 확인 가능
5.2. Impact of the choice of Teacher Network
Building different teachers from the student
Figure 6 우측에서 Teacher Network 생성 전략들을 비교합니다.
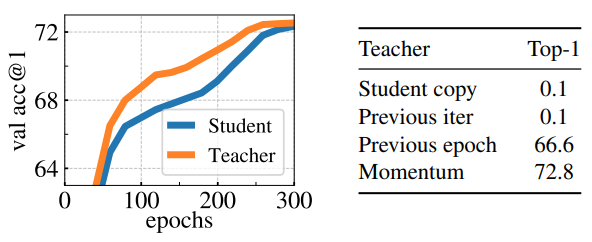
Analyzing the training dynamic
Figure 6(left)에서 DINO frameworks에서 Momentum Teacher가 왜 성능이 좋았는지 dynamic graph를 통해 확인합니다.
- 핵심은 Teacher의 성능이 학습 내내 Student 보다 좋았다는 것
- 이러한 양상은 다른 momentum을 쓴 frameworks에서는 발견되지 않음
- 그래서 DINO에서의 momentum teacher를 “Polyak-Ruppert averaging with exponential decay”로 해석
- Polyak-Ruppert averaging은 network ensemble에 많이 사용되는 방법.
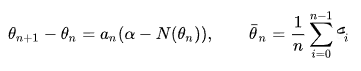
5.3. Avoiding collapse
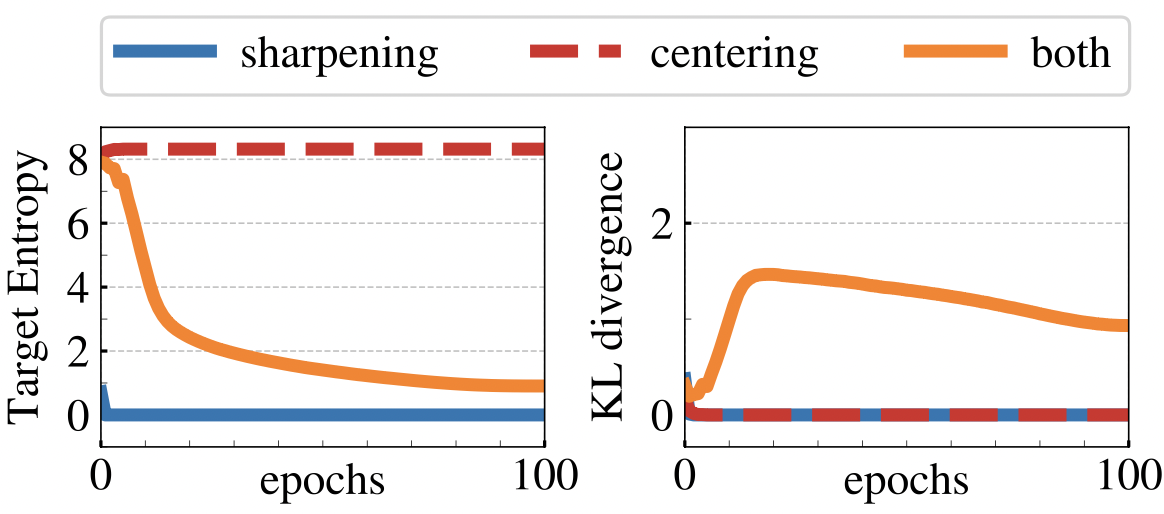
Collapsing은 두 가지 종류가 있는데, 첫 번 째는 모든 결과가 똑같은(uniform) 것이고, 다른 하나는 딱 하나의 결과로만(dominated) 나오는 것입니다. centering은 entropy를 증가시키고, sharpening은 그 반대입니다. 그래프 우측을 보면, sharpening, centering 둘 중 하나만 쓰면 KL divergence값이 0으로 collapse된 것을 확인할 수 있습니다.
5.4. Compute requirements
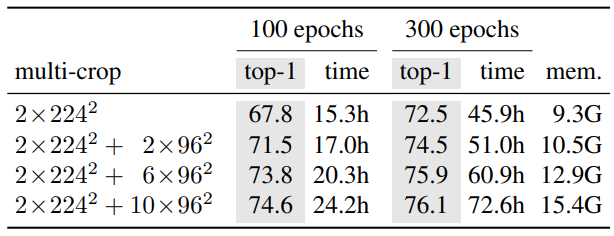
Table 8에는 ViT-S/16 DINO 모델의 two 8-GPU 환경에서 총 running time과 peak memory per GPU (mem)을 정리합니다. 결과를 보면 multi-crop에 따라 accuracy - running time trade-off를 확인할 수 있습니다.
- 1행은 multi-crop이 없는 경우: 46시간 후 72.5%
- 제한된 성능의 machine을 3일만 학습시켜서, 기존의 SOTA 성능을 outperform
5.5. Training with small batches
아래 Table 9은 multi-crop 없이 100 epochs를 학습 시켰을 때의 k-NN 성능입니다.
- default setting 1024
