
AI Hub 한국어 글자체 데이터셋 파이썬으로 불러오기
1. Intro
간단한 ocr 모형이 필요한데, 대부분의 ocr 엔진이 유료이고 Tesseract는 인식률이 너무 안 좋았다.
그래서 직접 만드려고 한국어 글자 데이터셋을 검색하니 AI Hub에서 (무려 무료로!) 방대한 한국어 글자체 이미지를 배포하고 있었다.
- 손글씨 370만장
- 인쇄체 280만장
- 실사 이미지 10만장
전체 파일의 용량은 압축 상태가 200Gb가 넘는다.
조금 짜증스러운 점은.. mac에서는 다운 받기 위한 프로그램을 설치해야 하고, 이어받기(?) 기능이 없어 한 번 프로그램을 잘못 종료하면 처음부터 다시 받아야 한다. (나는 당했다)
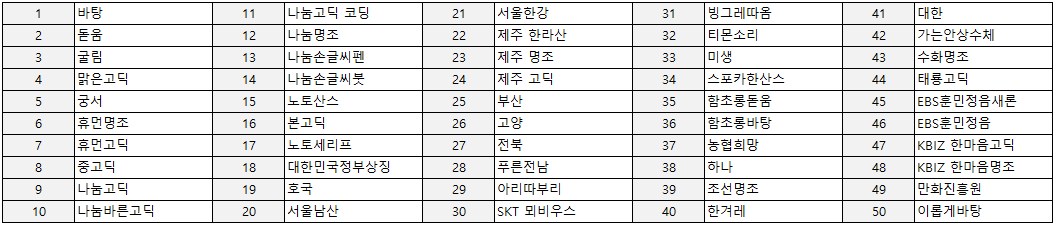
지원 폰트
인쇄체에서 지원되는 글자체(폰트)는 다음과 같은 50개나 된다.
데이터셋 전체 구조
전체 데이터는 다음과 같이 크게 손글씨, 인쇄체, 실사 데이터셋으로 구분돼있다. 각각의 데이터셋은 데이터셋 정보가 담긴 Json파일이 한 개씩 있어 그 파일을 참고하여 데이터를 선별할 수 있다.
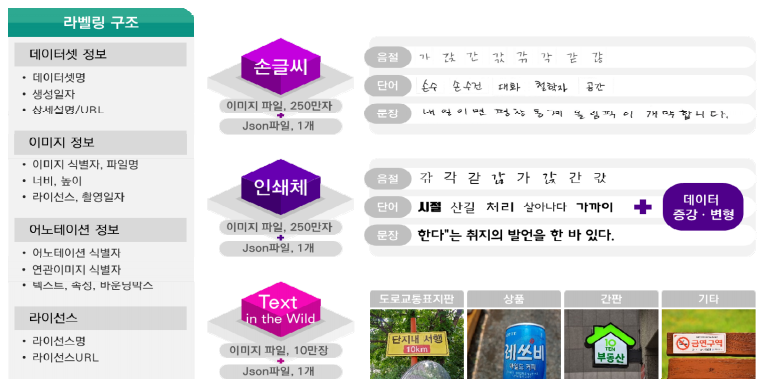
Json 구조
Json파일은 다음과 같은 구조이다. 파이썬에서 dict로 읽은 뒤, images와 annotations 부분을 가져오면 되겠다 싶다.

2. 전처리
일단 json파일을 읽어오자
import json
import pandas as pd
# json파일 읽어오기
base_path = './raw/한국어 글자체 이미지/02.인쇄체/'
file = json.load(open(base_path + 'printed_data_info.json'))
# json에서 images 부분 DataFrame으로 읽어오기
df_images = pd.DataFrame(file['images'])
annotations 부분도 읽어와야 하는데, dict 안에 dict가 있어서 파이썬의 list comprehension 기능으로 꺼내와야 한다.
annotations = [{'image_id':img['image_id'],
'text':img['text'],
'font':img['attributes']['font'],
'type':img['attributes']['type'],
'is_aug':img['attributes']['is_aug']} for img in file['annotations']]
df_annotations = pd.DataFrame(annotations)
그런데 폰트, 타입 등의 정보는 annotations에 있고, 파일명은 images에 있어서 두 개를 join해야 한다. join 후에는, 내가 필요한 조건의 글자만 가져올 수 있다.
df_all_info = pd.merge(df_annotations, df_images, left_on='image_id', right_on='id', how='left')
seoul = df_all_info[(df_all_info.font == '서울한강') & (df_all_info.type == '글자(음절)')]
잘 가져왔는지 살펴보자.
import matplotlib.pyplot as plt
import cv2
# image 그리기
def show_char(filen):
try:
img = cv2.imread(base_path+'syllable/'+filen)
except:
img = cv2.imread(base_path+'word/'+filen)
plt.imshow(img)
# test
show_char(seoul.iloc[0, 8])
show_char(seoul.iloc[375, 8])
그런데 파일 정보만 있고, 실제 파일이 없는 경우가 있다.. 데이터셋 구축 담당자에게 따져 물어야 하는거 아닌가? 일단 공짜로 받았으니 그냥 내가 처리한다.
# file check: id 기준 10637까지만 실제 파일 존재
for i in range(len(seoul)):
try:
show_char(seoul.iloc[i, 8])
except:
print("error id: ", i)
break
위와 같이 전체 정보를 활용해서 실제 파일을 그려보면 index번호 10,638에서부터 에러가 난다. 즉, 총 10,638개의 데이터만 있다는 뜻이다. 그러므로 없는 파일에 대한 정보는 삭제해주자.
# %% 데이터가 있는 만큼만
seoul = seoul[:10638]
# 파일명과 텍스트를 묶어 준비를 마친다
labels = list(zip(seoul.file_name, seoul.text))
img_labels = pd.DataFrame(labels)
파일명과 해당 파일의 텍스트를 묶어 데이터 준비를 마친다. 이후 여기에서 준비한 (파일명, 라벨) 세트를 활용하여, pytorch 패키지에서 파일을 바로 읽고 바로 분석할 계획이다.
결론
- Ai Hub에서는 공짜로 데이터를 준다.
- 그러나 데이터셋 설명을 무조건 믿지 말고, 확인 후 사용하자!